
10 Data Science Technical Job Interview Questions You Should Prepare before Your Interview as an Experienced Data Scientist
Intro
What Should I Study Before a Data Science Interview?
Data Science Job Interview Questions for Experienced - Technical
-
What is your opinion on supervised vs. unsupervised learning?
-
What are overfitting and underfitting?
-
Can Item2Vec be used in recommendation systems?
-
What are the Algorithms used for clustering?
-
What is the main problem with the k means clustering algorithm?
-
Which data package is used by Uber in its analysis?
-
What do you know about autoencoders?
-
What do you understand about the Boltzmann machine?
-
How do you find the Euclidean distance between two series in Python?
-
Which Machine Learning algorithm is best for credit card fraud detection?
Conclusion
It should be no surprise that data scientists help businesses to generate billions of dollars every year with their knowledge of statistical models and machine learning.
I won't go into detail about it here, but if you are the one preparing for technical data science job interview questions, use it for your preparation.
What Should I Study Before a Data Science Interview?

Prepare yourself to crack data science interviews. You should present a well-structured and organised resume summarising past experiences and skills.
It is always suggested that you highlight your enthusiasm to research more and learn more because there is no end to learning.
Data science job interview questions are mostly not unequivocal questions but rather bookish and technical.
Therefore, data science interviewees should have a good fundamental knowledge of the basics and knowledge of coding, SQL, software, algorithms, data structure, statistics, maths, and machine learning
Data Science Job Interview Questions for Experienced - Technical
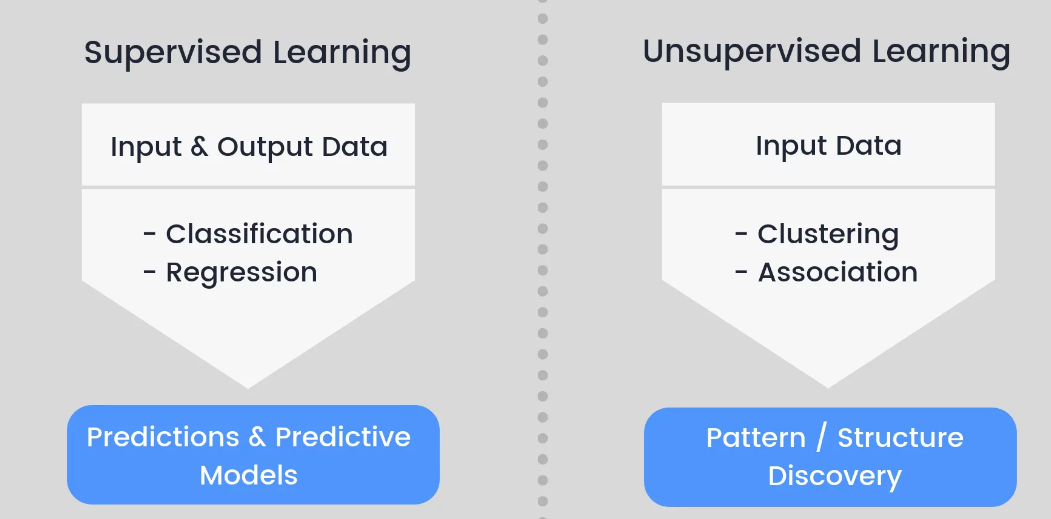
1. What is your opinion on supervised vs. unsupervised learning?
Supervised learning and unsupervised learning is an independent topic and both are different on labelled training data. Unsupervised learning relies on raw data and supervised machine learning uses output training data or labelled data as input.
Unsupervised learning always discovers inherent trends within a given set like k-means clustering, apriori algorithm, clustering, and hierarchical clustering.
On the other hand, supervised learning discovers the relationship between labelled input and output data by application of a support vector machine, logistic regression, and decision trees.
2. What are overfitting and underfitting?
Overfitting is when a model performs well for training data but has poor performance on the test data. Due to noise observed on the training data, the model performs negatively on the test data. Overfitting happens due to Low Bias & High Variance in the data.
Underfitting is when a model is unable to perform well on the training data which results in unreliable results on the test data as well. Underfitting happens due to High Bias & Low Variance in the data.
3. Can Item2Vec be used in recommendation systems?
Yes, the Item2Vec model can be used to produce a recommendation based on an algorithm, mostly it is for the Word2Vec recommendation system. Moreover, the Item2Vec model is helpful if there is the goal to offer an alternative recommendation based on reviews.
4. What are the Algorithms used for clustering?
A K-mean algorithm is used for centroid-based clustering. K-mean algorithms select k objects randomly for calculation based on the Euclidean Distance between the centroid. Moreover, through k clusters, you can update the distance between the centroid through mean values.
5. What is the main problem with the k means clustering algorithm?
If the data are of varied densities and sizes then k - clustering creates huge problems in clustering as it is very sensitive to outliers. In simple terms, it does not allow the data scientist to predict the number of clusters within the data.
6. Which data package is used by Uber in its analysis?

Uber uses a data package called ggplot2, tidyr, ggthemes, sclaes, and dplyr.
ggplot2: For statistical visualisation with graphs and charts.
Tidyr: In the creation of tidying the data. The main focus is to present variables in columns, observations in a row, and values in a cell.
Ggthemes:
This offers scales for ggplot2 and themes that make the project look good.
7. What do you know about autoencoders?
An error or bias in sampling happens because there are no definite target populations and sampling frames. Therefore, the introduction of an online survey, sampling, boosting, and following up on non-responders can avoid sampling bias.
8. What do you understand about the Boltzmann machine?
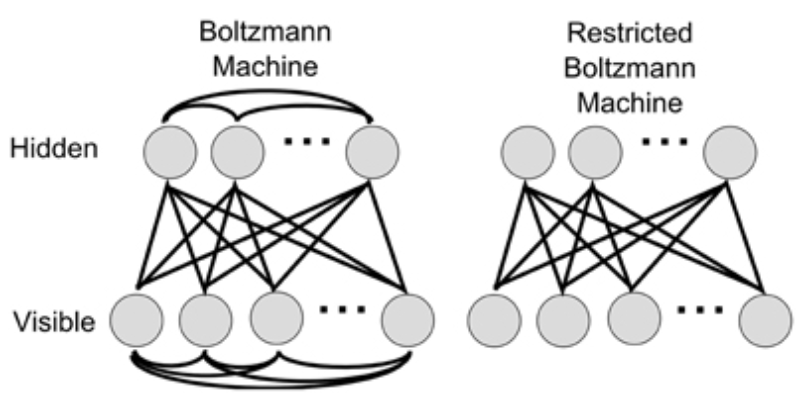
The Boltzmann machine or stochastic Hopfield is a recurrent neural network that offers a simple learning algorithm to ensure fascinating optimised training data for a given problem.
9. How do you find the Euclidean distance between two series in Python?
The Euclidean distance between two series in Python can be
generated through the numpy function.
Apart from that, you can calculate as,
Consider
plot1 = [1,3]
plot2 = [2,5]
Then, euclidean_distance = sqrt( (plot1[0]-plot2[0])**2 + (plot1[1]-plot2[1])**2 )
10. Which Machine Learning algorithm is best for credit card fraud detection?
Credit card fraud detection requires accuracy, therefore RF applied with v_5 should be applied to detect fraudulent activities. Logistic Regression, Gradient Boostin, Decision Trees, and Artificial Neural Network algorithms can also be used for the detection of fraud in credit cards.
There are so many data science job interview questions that urge us to prepare and study more. Particularly, taking a data science course and tutorials from businesstoys will help you. Our team dedicatedly prepares data scientists to be pros in their field.

Manikanta Prasad
Lead Data Scientist
Business Toys

Leave a comment
Your email address will not be published. Required fields are marked with *